python使用request获取实时数据并绘制图形
使用API调用请求数据
本示例使用GITHUB的API来请求有关该网站中PY项目的信息,并使用Pygal生成交互式可视化。
https://api.github.com/search/repositories?q=language:python&sort=stars上面这个地址,返回github当前托管了多少个py项目,还有有关最受欢迎的PY仓库的信息。
{
total_count: 17592022, // 项目总数
incomplete_results: true, // 如果github无法全面处理该API 它返回的值是true; false代表请求成功,并且展示的结果是全部、完整的
items: [] // 每一项的信息
}接口中各个参数解析:
search/repositories:让API搜索GITHUB上所有仓库
q=language:python:q表示查询,language:python 指出只想获取py仓库的信息
sort=stars:按照星级进行排序
requests
pip install --user requests先来做一个简答的请求
import requests
# 执行API调用并存储响应
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
r = requests.get(url)
print('status code', r.status_code)
# 将API响应存储
response_dict = r.json()
print(response_dict.keys())最终运行结果:
status code 200
dict_keys(['total_count', 'incomplete_results', 'items'])r.status_code:获取本次请求的状态码,200表示请求成功
response_dict = r.json():将这些信息转换为一个py字典,并用变量接收
response_dict.keys():打印字典中的“键”
从github数据中获取数据内容并保存在文件中
import requests
# 需要导入json模块处理JSON序列化
import json
# 执行API调用并存储响应
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
r = requests.get(url)
print('status code', r.status_code)
savefile = 'github-py=repositories.json'
with open(savefile, 'w', encoding='utf-8') as sf:
# 直接写入文件
json.dump(r.json(), sf, ensure_ascii=False, indent=2)
# 使用json.dumps()转换为字符串再写入
# json_str = json.dumps(r.json(), ensure_ascii=False, indent=2)
# sf.write(json_str)
# 将API响应存储
# r.json()返回的是 Python 字典对象
response_dict = r.json()
# print(response_dict.keys())
print('github总共包含的py仓库数是:', response_dict['total_count'])
# 获取有关仓库信息
# items是一个列表,其中的每个字典都包含了一个仓库信息
repo_dicts = response_dict['items']
print('一共多少项', len(repo_dicts))
# 研究第一个仓库
repo_dict = repo_dicts[0]
# print('keys', len(repo_dict))
# sorted按照键(字母)排序
for key in sorted(repo_dict.keys()):
print(key)
# 打印第一个仓库的信息
print('打印第一个仓库的信息:')
print('name', repo_dict['name'])
print('owner', repo_dict['owner']['login'])
print('stars', repo_dict['stargazers_count'])
print('repository', repo_dict['html_url'])
print('created', repo_dict['created_at'])
print('updated', repo_dict['updated_at'])
print('description', repo_dict['description'])这里主要讲一下json.dump和json.dumps。
当我们使用request获取到内容,然后执行r.json时,获取的实际是一个字典:
r = requests.get(url)
json_dict = r.json() // 获取的是一个字典而字典是无法直接写入文件的,必须使用字符串。我们可以使用json.dumps 将字典转化为字符串然后再写入:
# 方法2:使用json.dumps()转换为字符串再写入
with open(savefile, 'w', encoding='utf-8') as sf:
json_str = json.dumps(r.json(), ensure_ascii=False, indent=2)
sf.write(json_str)json.dumps()是 Python 标准库中json模块的一个重要函数,其作用是将 Python 对象(如字典、列表等)转换为 JSON 格式的字符串。这个过程也被称为序列化,主要用于数据交换、存储或网络传输。这里dumps后面的s指将对象转换为字符串(s表示 string)。 常用参数
obj:需要转换的 Python 对象(通常是字典或列表)。ensure_ascii:True(默认):将非 ASCII 字符转义为\uXXXX格式(如中文会变成\u4e2d)。False:直接保留非 ASCII 字符(如中文直接显示为你好)。
indent:指定缩进空格数,用于美化输出。例如indent=2会生成格式化的 JSON。sort_keys:是否按键排序字典。True会让输出的 JSON 键按字母顺序排列。
注意:使用dumps转换后需要手动写入:
json_str = json.dumps(data) # 返回字符串
file.write(json_str) # 需要手动写入文件还有另外一种方式:dump(),直接将对象写入文件(dump表示倾倒)。
# 方法1:使用json.dump()直接写入文件(推荐)
with open(savefile, 'w', encoding='utf-8') as sf:
json.dump(r.json(), sf, ensure_ascii=False, indent=2)比如一个基本例子:
with open('data.json', 'w') as f:
json.dump(data, f) # 自动写入文件,无需手动转换获取github项目数据配合pygal生成图表
import requests
import json
import pygal
from pygal.style import LightColorizedStyle as LCS, LightenStyle as LS
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
r = requests.get(url)
response_dict = r.json()
repo_dicts = response_dict['items']
names, plot_dicts = [], []
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
plot_dict = {
# 星数
'value': repo_dict['stargazers_count'],
# 项目描述
'label': repo_dict['description'],
# 为每个条形 添加可点击的链接
'xlink': repo_dict['html_url']
}
plot_dicts.append(plot_dict)
# 可视化
my_style = LS('#333366', base_style=LCS)
chart = pygal.Bar(
style=my_style,
x_label_rotation=45,
show_legend=False
)
chart.title = 'py图表'
chart.add('', plot_dicts)
chart.render_to_file('python_repos_250610.svg')这里通过:plot_dicts.append(plot_dict) 构建一个字典集合的数组,然后在图表中传入这个数组即可。当然字典中比如value、label这些字段都是固定的。传入xlink字段,那么每个条形图都会赋予一个点击的外链。
请求技术类汇总文章
import requests
from operator import itemgetter
#执行API调用并存储响应 获取最热门的文章
url = 'https://hacker-news.firebaseio.com/v0/topstories.json'
r = requests.get(url)
print('topstories status code', r.status_code)
# 处理有关每篇文章的信息
submission_ids = r.json()
submission_dicts = []
for submission_id in submission_ids:
# 对于每篇文章 都执行一个API调用
suburl = ( 'https://hacker-news.firebaseio.com/v0/item' + str(submission_id) + '.json' )
submission_r = requests.get(suburl)
print('submission_id:', submission_r.status_code)
response_dict = submission_r.json()
submission_dict = {
'title': response_dict.get('title', '没有标题'),
'link': 'http://news.ycombinator.com/item?id=' + str(submission_id),
# 获取每篇文章的评论数 get()方法是获取字典中的键,如果没有键descendants 那么久指定一个默认值
# 不确定某个键是否包含在字典中时,可使用方法dict.get('键名', 默认值)
'comments': response_dict.get('descendants', 0)
}
submission_dicts.append(submission_dict)
# 对字典列表进行排序 key是指定按照哪个键排序
# operator模块中的itemgetter,itemgetter('comment') 它将从这个列表的每个字典中提取与键comments相关联的值
# 这样sorted根据这种值对列表进行排序 reverse=True是按降序排列
submission_dicts = sorted(submission_dicts, key=itemgetter('comment'), reverse=True)
for submission_dict in submission_dicts:
print('\ntitle', submission_dict['title'])
print('discussion link:', submission_dict['link'])
print('comments', submission_dict['comments'])这里面有两个知识点需要讲一下:
dict.get()
get()方法是获取字典中的键,如果没有包含指定的键那么就指定一个默认值
不确定某个键是否包含在字典中时,可使用方法dict.get('键名', 默认值)
data = [
{
'name': 'Alice',
'age': 25,
'city': 'New York'
},
{
'name': 'Bob',
'age': 22,
'city': 'Los Angeles'
},
{
'name': 'Charlie',
'age': 30,
'city': 'Chicago'
}
]
for ditem in data:
print(ditem.get('real', '没有这个'))itemgetter
itemgetter是 Python 标准库operator模块中的一个工具,用于创建一个可调用对象,该对象可以从其操作数中获取指定位置的元素。简单来说,它可以帮助你快速获取序列(如列表、元组)或映射(如字典)中的特定元素。
from operator import itemgetter
data = [
{'name': 'Alice', 'age': 25, 'city': 'New York'},
{'name': 'Bob', 'age': 22, 'city': 'Los Angeles'},
{'name': 'Charlie', 'age': 30, 'city': 'Chicago'}
]
# 创建获取 'name' 字段的函数
get_name = itemgetter('name')
# 方法一:使用循环遍历并调用 get_name
for item in data:
print(get_name(item)) # 输出: Alice, Bob, Charlie
# 方法二:直接在循环中使用 itemgetter
for item in data:
print(itemgetter('name')(item)) # 等价写法
# 方法三:列表推导式获取所有名字
names = [get_name(item) for item in data]
print(names) # 输出: ['Alice', 'Bob', 'Charlie']itemgetter('name')返回一个函数,需要传入字典作为参数才能获取对应的值,例如get_name(item)。
函数式编程:itemgetter('name')(item)
itemgetter('name')是一个工厂函数,它会创建并返回一个新的函数,我们可以称之为name_getter。这个新函数的作用是:从输入对象中提取'name'字段的值。
所以get_name = itemgetter('name') 实际获得的就是一个函数!
itemgetter('name')(item)怎么理解?
这其实是连续调用两个函数:
- 第一步:
itemgetter('name')返回一个函数(比如叫get_name)。 - 第二步:立即调用这个新函数
get_name(item),传入参数item(这里是一个字典)。
# 分解写法
name_getter = itemgetter('name') # 创建获取 'name' 的函数
name_value = name_getter(item) # 调用函数,传入字典 item
# 等价于一行写法
name_value = itemgetter('name')(item)itemgetter是用 C 语言实现的,比 Python 写的lambda x: x['name']更快
itemgetter同样也可以传入数字索引。
from operator import itemgetter
# 创建一个列表
data = [('Alice', 25, 'New York'), ('Bob', 22, 'Los Angeles'), ('Charlie', 30, 'Chicago')]
# 使用 itemgetter 创建一个获取第 1 个元素(索引 0)的函数
get_name = itemgetter(0)
# 对列表中的每个元素应用 get_name 函数
names = [get_name(person) for person in data]
print("Names:", names) # 输出: ['Alice', 'Bob', 'Charlie']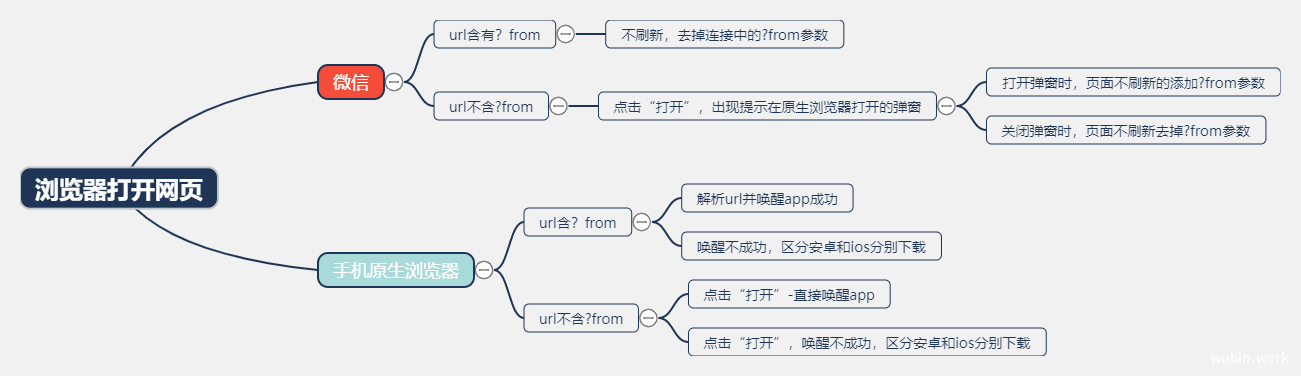






 目录
目录